- Learning outcomes
- First steps
- Accessing the data
- Share of valid words
- Share of uncommon words
- Conclusion
- References
Learning outcomes
In this tutorial you learn the steps needed to calculate and visualize some measures of languages development over time for three children, using R and the CHILDES database of child language development. You will need these skills in the small homework assignment following this workshop, and in case you choose to complete a data assignment instead of an experiment for your final poster.
You learn how to import data into R with the childesr package, how to
use basic text analysis tools, and how to visualize your results using
the ggplot2 package.
First steps
This tutorial assumes that you completed the first Data Center workshop and its prerequisites.
Note that if you get stuck at any point, check the help files of
functions (access by running ?functionname), look at more extensive
Data Center tutorials, try googling your question,
attend Data Center office hours (schedule) or email
datacenter@ucr.nl.
The code used in this tutorial is also available on Github.
Accessing the data
Our goal is to analyze speech samples from three children, calculate different measures of language development, and visualize the results. All three children were studied by Roger Brown and his students, and their data is available in the CHILDES database.
First, we load the packages we need for this analysis. Make sure that
all packages are installed on your computer. If not, you can install
them by running install.packages("packagename").
# load packages
library(tidyverse)
library(childesr)
library(qdapDictionaries)
# look at all the available corpora in the data set
corpora <- get_corpora()
View(corpora)
We are going to work with tokens and utterances a lot, so first, a little explanation on what they actually are. Utterances are data elements from a recorded piece of conversation (such as “I had good dinner”). Tokens are specific pieces of utterances (“I”, “had”, “good”, “dinner”). Utterances are usually more useful when we look into the development of a child as a whole (syntax, semantics, context of the utterance), whereas with tokens you can look into the development of a child’s vocabulary (child’s vocabulary complexity and its development over time.)
When picking a child/children for your research question, it is very important to make sure you have enough data (utterances and tokens) to work with. In a study done by MacWhinney, B., & Snow, C. (1990) you have a detailed overview of all the researchers who have added to the childes data set. There are some which follow a single child (Snow), some that look into the short-term speech of multiple children (Higginson), and some that follow the mothers and children as well (Howe).
In this example, we will work with Brown’s addition to the data set (Brown’s corpora, specifically tokens) - data acquired from three children Adam, Eve and Sarah, collected by Roger Brown and his students. Adam was studied from 2;3 to 4;10; Eve from 1;6 to 2;3; and Sarah from 2;3 to 5;1.
# download tokens from the Brown corpus
tokens <- get_tokens(token = "*", collection = "Eng-NA",
corpus = "Brown", role = "target_child")
Share of valid words
One way to measure the development of the children’s language using token-level data is to evaluate whether each token is a valid English word or not, and use this information to calculate summary statistics per time period.
We can introduce a variable for whether the each word is present in an
English dictionary. This variable will be a logical vector, with TRUE
and FALSE as possible values. The computer treats TRUE values as 1
and FALSE values as 0, so you can use mathematical operations such as
averages on logical data. Then the average of the variable over a
certain time period can be interpreted as the share of words that are
present in an English dictionary: average values closer to zero would
mean the child still has a lot of mumbling/incorrect pronunciation or
misspoken words in their vocabulary, whereas a child with a score near 1
has a very developed vocabulary. This way, we can assign a value to
every token, and then average it per certain time period. Afterwards, we
can compare this value progression for all three children. This
comparison does not look into syntax of the sentence, meaning that even
a sentence “banana mango apples man” would be evaluated as entirely
correct, when in reality this sentence is nonsensical. So this method
certainly has its limitations, but is nevertheless interesting to look
at.
In order to find out which words exist in an English dictionary, we need
to choose a dictionary. The qdapDictionaries package contains the
GradyAugmented object, which is a character vector containing over
120,000 English words.
# let's check the total number of words in the GradyAugmented vector
length(GradyAugmented)
## [1] 122806
It is suggested by multiple sources that we need approximately 3000 words to be able to communicate our point in English without any problems (VocabularyFirst, 2019; Yang, 2016). This data set has 40 times that amount, so we can deem it appropriate for our purposes. Even though it’s not an exhaustive list of all English words, the chances that a child said a word that is correct and is not on the list above is very small.
Now we need to compare the data sets of children’s tokens with the valid
words in our English dictionary. We can define a logical condition with
the %in% operator, which checks if each token is present in the
GradyAugmented vector and returns TRUE or FALSE as the result. We
call the new variable is_valid to reflect whether the token in each
row is a valid word.
# Create a new column 'is_valid' in tokens
valid_tokens <- tokens %>%
mutate(is_valid = gloss %in% GradyAugmented)
# View the first few rows of gloss and is_valid to check the results
valid_tokens |>
select(gloss, is_valid) |>
head()
## # A tibble: 6 × 2
## gloss is_valid
## <chr> <lgl>
## 1 yeah TRUE
## 2 choo_choo FALSE
## 3 train TRUE
## 4 there TRUE
## 5 water TRUE
## 6 water TRUE
Since these children are not studied from the time when they first start speaking and are therefore more likely to stutter or create their own words to fill in gaps in vocabulary, most tokens are valid words. However, there will still be some slips, such as when Adam used the word choo-choo, probably to adress a train.
Looking at these “slips” may show us how developed a child’s language is. In reality, creating their own words and bridging gaps in their vocabulary is just a natural step in language development, as it is experimentation with meaning, words structures and sounds (Michigan State University Extension, 2023, Social Sci LibreTexts, 2023). However, for us it shows how “far” a child is in their language development journey.
In order to get some statistics over time, let’s aggregate the data per
child and age bracket, and calculate the share of valid words in each
period. We use the floor() function to round the age to the nearest
month, and then group by the child’s name and age bracket to calculate
the average of the is_valid variable.
valid_tokens <- tokens |>
mutate(is_valid = gloss %in% GradyAugmented,
age = floor(target_child_age)) |>
group_by(target_child_name, age) %>%
summarise(valid_share = mean(is_valid))
Once we have the data where each row corresponds to one child in one month, we can visualize the data with a line chart, coloring the lines by child name.
valid_tokens |>
ggplot(aes(x = age, y = valid_share, color = target_child_name)) +
geom_line() +
labs(title = "Development of Average Valid Word Usage Over Time",
x = "Age (months)",
y = "Average Valid Word Usage") +
theme_minimal()
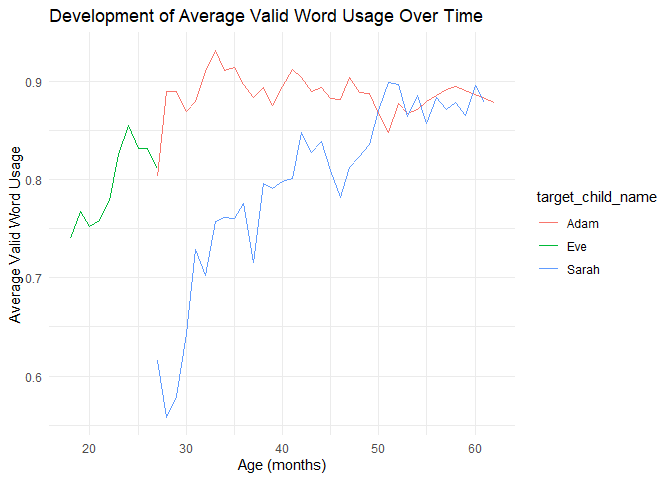
After looking at the data we can see that initially, there is an increase of average valid word usage, especially for Sarah. However, there does not seem to be a stable trend, except for Eve, where there is a stable increase for period of 5 months. Her speech was recorded for shorter period of time than Adam and Sarah and at a younger age, so it’s not an entirely fair comparison with the other two. When we compare only Adam and Sarah, we can see that Adam started with a much higher average valid word usage, but Sarah caught up to Adam over time, and from about the age of 50 months, they have similar average valid word usage (85–90% of all tokens).
This way of analyzing tokens may be more suitable for children that are just learning how to speak, as the figure suggests that there is a certain development period of life when there is a rise of average valid use of words, and then the trends flatten out as the vast majority of spoken tokens are valid words beyind a certain age.
Share of uncommon words
Another way we can analyse and compare their vocabulary development is to look into the uniqueness of words the children use. For this we will track “valid” words from their utterances, but compare it against the 500 most common words in the English language to see how many words are NOT from this list (while still being valid words). So instead of calculating what share of total tokens are valid words, we can calculate what share of total tokens are valid but not common words.
First, let’s create a vector with the most common words according to english4today.com. There is no pre-defined list of the most common words in R, so we have to create it ourselves.
Useful tip: AI tools such as ChatGPT can help with formatting words/numbers into data sets and vectors.
# create a vector with the provided list of common words
common_words <- c("the", "of", "to", "and", "a", "in", "is", "it", "you", "that", "he",
"was", "for", "on", "are", "with", "as", "I", "his", "they", "be",
"at", "one", "have", "this", "from", "or", "had", "by", "hot", "but",
"some", "what", "there", "we", "can", "out", "other", "were", "all",
"your", "when", "up", "use", "word", "how", "said", "an", "each",
"she", "which", "do", "their", "time", "if", "will", "way", "about",
"many", "then", "them", "would", "write", "like", "so", "these",
"her", "long", "make", "thing", "see", "him", "two", "has", "look",
"more", "day", "could", "go", "come", "did", "my", "sound", "no",
"most", "number", "who", "over", "know", "water", "than", "call",
"first", "people", "may", "down", "side", "been", "now", "find",
"any", "new", "work", "part", "take", "get", "place", "made", "live",
"where", "after", "back", "little", "only", "round", "man", "year",
"came", "show", "every", "good", "me", "give", "our", "under", "name",
"very", "through", "just", "form", "much", "great", "think", "say",
"help", "low", "line", "before", "turn", "cause", "same", "mean",
"differ", "move", "right", "boy", "old", "too", "does", "tell",
"sentence", "set", "three", "want", "air", "well", "also", "play",
"small", "end", "put", "home", "read", "hand", "port", "large",
"spell", "add", "even", "land", "here", "must", "big", "high", "such",
"follow", "act", "why", "ask", "men", "change", "went", "light",
"kind", "off", "need", "house", "picture", "try", "us", "again",
"animal", "point", "mother", "world", "near", "build", "self",
"earth", "father", "head", "stand", "own", "page", "should", "country",
"found", "answer", "school", "grow", "study", "still", "learn",
"plant", "cover", "food", "sun", "four", "thought", "let", "keep",
"eye", "never", "last", "door", "between", "city", "tree", "cross",
"since", "hard", "start", "might", "story", "saw", "far", "sea",
"draw", "left", "late", "run", "don't", "while", "press", "close",
"night", "real", "life", "few", "stop", "open", "seem", "together",
"next", "white", "children", "begin", "got", "walk", "example", "ease",
"paper", "often", "always", "music", "those", "both", "mark", "book",
"letter", "until", "mile", "river", "car", "feet", "care", "second",
"group", "carry", "took", "rain", "eat", "room", "friend", "began",
"idea", "fish", "mountain", "north", "once", "base", "hear", "horse",
"cut", "sure", "watch", "color", "face", "wood", "main", "enough",
"plain", "girl", "usual", "young", "ready", "above", "ever", "red",
"list", "though", "feel", "talk", "bird", "soon", "body", "dog",
"family", "direct", "pose", "leave", "song", "measure", "state",
"product", "black", "short", "numeral", "class", "wind", "question",
"happen", "complete", "ship", "area", "half", "rock", "order", "fire",
"south", "problem", "piece", "told", "knew", "pass", "farm", "top",
"whole", "king", "size", "heard", "best", "hour", "better", "true",
"during", "hundred", "am", "remember", "step", "early", "hold", "west",
"ground", "interest", "reach", "fast", "five", "sing", "listen", "six",
"table", "travel", "less", "morning", "ten", "simple", "several",
"vowel", "toward", "war", "lay", "against", "pattern", "slow", "center",
"love", "person", "money", "serve", "appear", "road", "map", "science",
"rule", "govern", "pull", "cold", "notice", "voice", "fall", "power",
"town", "fine", "certain", "fly", "unit", "lead", "cry", "dark",
"machine", "note", "wait", "plan", "figure", "star", "box", "noun",
"field", "rest", "correct", "able", "pound", "done", "beauty", "drive",
"stood", "contain", "front", "teach", "week", "final", "gave", "green",
"oh", "quick", "develop", "sleep", "warm", "free", "minute", "strong",
"special", "mind", "behind", "clear", "tail", "produce", "fact",
"street", "inch", "lot", "nothing", "course", "stay", "wheel", "full",
"force", "blue", "object", "decide", "surface", "deep", "moon", "island",
"foot", "yet", "busy", "test", "record", "boat", "common", "gold",
"possible", "plane", "age", "dry", "wonder", "laugh", "thousand", "ago",
"ran", "check", "game", "shape", "yes", "hot", "miss", "brought", "heat",
"snow", "bed", "bring", "sit", "perhaps", "fill", "east", "weight",
"language", "among")
Now let’s create a new variable in the tokens data that counts the
number of less common valid words. We can do this step by step: first,
we create a variable that checks if the word is in the vector of valid
words, another variable that checks if the word is in the vector of
common words, and finally a variable that checks if the word is valid
but not common. The ! operator negates the condition, so !is_common
is TRUE when is_common is FALSE.
# create the 'is_special' variable
special_tokens <- tokens |>
mutate(is_valid = gloss %in% GradyAugmented,
is_common = gloss %in% common_words,
is_special = is_valid & !is_common)
Now we can aggregate and plot the data the same way as before, this time calculating the share of special words per month for each child.
# share of special words per month
special_tokens <- tokens |>
mutate(is_valid = gloss %in% GradyAugmented,
is_common = gloss %in% common_words,
is_special = is_valid & !is_common,
age = floor(target_child_age)) |>
group_by(target_child_name, age) |>
summarize(special_share = mean(is_special))
# create the plot
special_tokens |>
ggplot(aes(x = age, y = special_share, color = target_child_name)) +
geom_line() +
labs(title = "Share of Special Words per Age Bracket",
x = "Age (months)",
y = "Share of Special Words") +
theme_minimal()
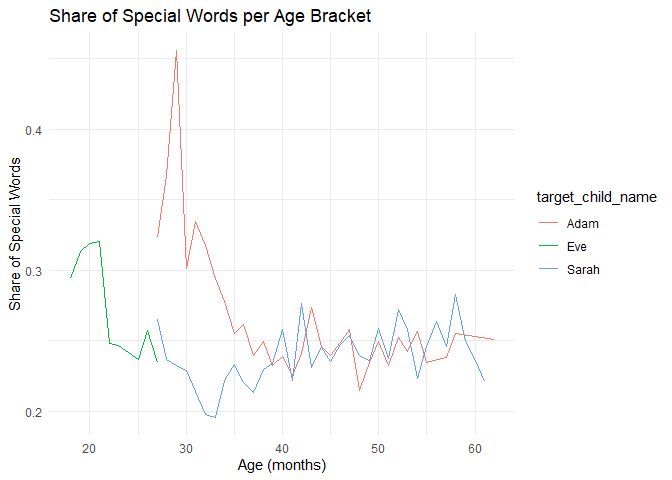
Thisp plot shows us that the share of special words is quite volatile over time, with little clear trends. For Eve, the share of special words decreases over time from above 30% to 25%, while for Adam there is a peak above 45% at around 30 months, followed by fluctuations around 25%. Sarah’s special word usage also fluctuates around 25%, with a slight dip to 20% at around 33 months. This result is not what we might have expected, as we might have thought that the share of special words would increase over time as the children expand their vocabulary.
A potential issue with this measure is that it counts every time a word is repeated. So we don’t know if a child uses 100 different words or the same word 100 times.
As an alternative measure, we can consider the share of unique special words out of the total number of unique words. So e.g. if a child says 1000 unique tokens in a month, out of which 200 are valid but not common words, the share of unique special words would be 200/1000=20%, no matter how many times each unique token is used. We can calculate this alternative metric by adding one line of code that keeps only unique combinations of child name, age, token, and special word indicator.
# share of unique special words per month
unique_special_tokens <- tokens |>
mutate(is_valid = gloss %in% GradyAugmented,
is_common = gloss %in% common_words,
is_special = is_valid & !is_common,
age = floor(target_child_age)) |>
# keep only unique tokens per child and age bracket
distinct(target_child_name, age, gloss, is_special) |>
group_by(target_child_name, age) |>
summarize(special_share = mean(is_special))
# create the line plot
unique_special_tokens |>
ggplot(aes(x = age, y = special_share, color = target_child_name)) +
geom_line() +
labs(title = "Share of Special Words per Age Bracket",
x = "Age (months)",
y = "Share of Special Words") +
theme_minimal()
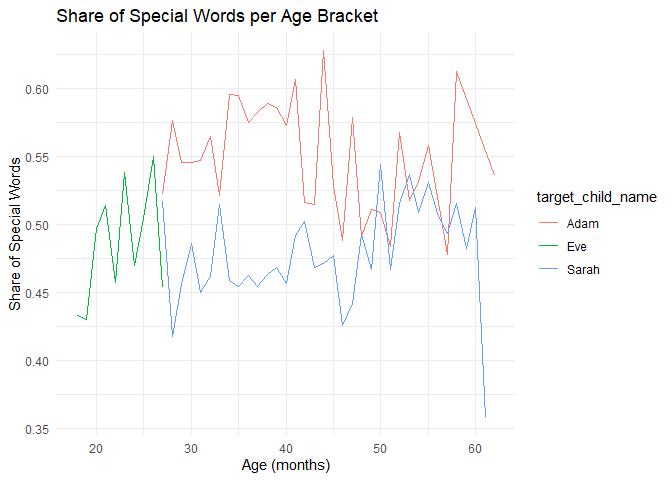
This plot looks very different than the previous one, but it doesn’t look much more informative. For all three children, the lines are very volatile with no clear trends over time. But if we compare the children, we see that up to the age of 50 months, Adam has a higher share of unique special words than Sarah, which is similar to the previous finding that in that age perid Adam also has a higher share of valid words.
Both of these methods have the limitation that we restrict the definition of common words to the 500 most common words. According to Linguisystems Milestones Guide the typical vocabulary size of a 5-year-old is between 2200-2500. So our definition of common words is quite restrictive, and we might miss some words that are common in the context of the children’s environment. These differences in environment might also esxplain the large fluctuations between transcript recordings. Of course, you can always look for a more extensive list of common words, or even create your own list based on the data you have. You can try to redefine the list of common words, rerun the analysis. and see if the results change.
Conclusion
In this example we analyzed the speech patterns of three children on the token level. We looked at whether the words they use are valid English words, and whether they are more common or more unique. While we found some evidence that the children’s language development progresses over time, the results are not as clear-cut as we might have expected, as all measures we tested are quite volatile. We also didn’t do any analysis on the syntax of the sentences, which is also an important part of language development. For that, we would need to look at the utterance level, and analyze the structure of the sentences, the length of the utterances, the complexity of the utterances, etc.
References
List of sources: Hsu, M.-L. (2013). Language play: The development of linguistic consciousness and creative speech in early childhood education. In Advances in early education and day care (Vol. 17, pp. 127–139). Emerald Group Publishing Limited. [https://doi.org/10.1108/S0270-4021(2013)0000012007][https://doi.org/10.1108/S0270-4021(2013)0000012007]{.uri}
The Education Hub. (n.d.). Effective vocabulary instruction. The Education Hub. https://theeducationhub.org.nz/effective-vocabulary-instruction/
Childes-db. (2019). Childes-db: A flexible and reproducible interface to the child language data exchange system. Journal of Child Language, 51, 1928–1941. https://doi.org/10.1017/s0305000900013866
WordReference. (n.d.). Top 2000 English words. WordReference. https://lists.wordreference.com/show/Top-2000-English-words.1/
VocabularyFirst. (2019). How many words do I need to speak English language? VocabularyFirst. https://www.vocabularyfirst.com/how-many-words-do-i-need-to-know/
Yang, D. (2016). How many words do you need to know to be fluent in English? Day Translations. https://www.daytranslations.com/blog/how-many-words-to-be-fluent-in-english/
Social Sci LibreTexts. (2023). Language Development in Early Childhood.
Michigan State University Extension. (2023). Language development – Part 2: Principles that are the stem and branch of speech.